





txt:後藤真理絵(ヤフー株式会社) 構成:編集部
Ethical AIとは何か
2019年3月8日~3月13日まで、米国テキサス州オースティンで開催されたSXSW2019に参加してきました。昨年と同様、主にインタラクティブ部門のセッションとTrade Showへの参加でした。
今回の参加テーマは、「AIを活用する組織/企業・市民・社会の共存」。普段の業務では、データサイエンスに近い領域で働いているため、アルゴリズムによって何らかの自動的な意思決定がなされることは身近なのですが、それが日常生活の中で当たり前のように使われるようになるには社会から受容される必要があります(いわゆる社会実装)。
昨今、GAFAを代表とするさまざまなグローバルのテクノロジー企業におけるユーザーデータの取り扱いについて、課題を指摘する記事を見かけるようになり、またそれらの企業は自らAI倫理を発表しています。また海外では政府がAIのガイドラインを制定するなどの動きがあります。
今回のSXSW2019では、そうした問題の当事者であるテクノロジー企業とアカデミックのAI研究者、政府など様々な立場が「どうあるべきか」を考えるとともに、AIやデータを使ってより良い未来を作るためのアイデアを共有するセッションが多数ありました。
セッション一覧の発表と同時に、SXSW2019の全体的なキーワードが「Ethical」「Humanity」であることに気づき、Ethical AIとは何か、ユーザーの変化とそれに伴う企業に対する期待値の変化について、メインで回ってきた1週間となりました。
中でも印象に残った6つのセッションを中心に、データオタクなりの振り返りをしたいと思います。
聴講した主なセッション一覧
■Digital Trends and the Impact of Privilege
Tanarra Schneider氏(Fjord/Accenture)■Featured Session: 2019 Emerging Tech Trends Report
Amy Webb氏(Future Today Institute)■Empathetic Technology and the End of the Poker Face
Poppy Crum氏(Dolby Laboratories)■How Heartbeats Are Redesigning Human Experiences
Eco Moliterno氏(Accenture Interactive)■Dear Gov’t: Regulate Us! Sincerely, AI Industry
Jean-François’ Gagné氏(Element AI)■Bias in, Bias Out: Building Better AI
Ashley Casovan氏(Government of Canada)
Kasia Chmielinski氏(The Data Nutrition Project/MIT)
Vikash Mansinghka氏(MIT)
M. Alejandra Parra-Orlandoni氏(Quantumblack a McKinsey Company)
ユーザーの変化
2018年にリリースされたOSから、iPhoneやAndroidスマホに、スマホ使用時間が表示されるようになりました。これはデジタルデトックスという潮流を受けたものです。
私たちは、日常生活において、スマホに限らず様々な場所でスクリーンに触れています。スクリーンを通じて、ユーザーは常に広告や通知、ニュース、ソーシャルメディアの友人の動向を気にするようになったことで、日常生活が常に注意散漫な状態となり、「スマホ疲れ」「ソーシャル疲れ」「スマホ肩」といった心身の不調を引き起こすことが問題視されたのです。
2018年10月にキックスターターで募集された「スクリーンをすべて隠すメガネ」がわずか3ヶ月で資金調達を達成したことも象徴的といえるでしょう。
この動きからFjordのセッションで提唱された「Mindful Design」というデザインのあり方に関するアイデアは印象に残りました。Mindful Designとは、Mindfulnessに由来する考え方です。Mindfulnessは、様々な定義がありますが、ここでは一番近い定義として「注意散漫になることなく、今の瞬間に意識を向ける精神状態」としたいと思います。
ユーザーは日常生活を送る上で、自分のペースを守り、自分の人生において大事なことに集中し、気付きを得たり安心を感じたりすることを重視するようになりました。より人間らしい生活への回帰といえるかもしれません。このためには、企業はユーザーに対して極力邪魔をせず、静かに、サービスを提供する必要があります。それがMindful Designです。
Mindful Designには3つの要素があると言われています。
- immediacy(即時性)
- accuracy(きめ細かい・的確)
- highly personalized(個別対応)
ユーザーの状況を察し、手を煩わせたりイライラさせたりしないシンプルな操作で豊かな体験を提供することが求められています。
ユーザーの心理を読む技術の実用化
ユーザーの状況を察するには、置かれている環境やシチュエーション、心理状態を、人間と同様に近いレベルで「感じる」ことが重要になってきます。この領域は「Empathetic Technology(共感するための技術)」と呼ばれ、様々な技術が研究段階から実用性が確認できる段階になってきていることが、複数のセッションで紹介されました。

生体データによって計測・判断可能になるコンテキストと感情
【出典】
Featured Session: 2019 Emerging Tech Trends Report:Amy Webb氏(Future Today Institute)
Empathetic Technology and the End of the Poker Face:Poppy Crum氏(Dolby Laboratories)
How Heartbeats Are Redesigning Human Experiences:Eco Moliterno氏(Accenture Interactive)
上記のセッションを元に筆者作成
上記の図のように「スマートデバイス」を通じて生体認証や生体データの計測を行うことにより、その人が置かれている環境と心理状況をある程度精度高く把握することが可能になってきています。
この領域のサイエンティストであるPoppy Crum氏のセッションでは、被験者に火の映像を見せたとき、皮膚からの放熱量が高くなる実験結果があり、目の間に火がなくても、視覚情報によって身体が反応することが確認されています(図1)。
 (図1)視覚からの刺激による皮膚の放熱量の高まり
(図1)視覚からの刺激による皮膚の放熱量の高まり【出典】Empathetic Technology and the End of the Poker Face:Poppy Crum氏(Dolby Laboratories)
上記のセッションで撮影
Poppy Crum氏のセッションでは、耳の形状によって聞こえ方やトーンが違うことが紹介されました。身体的な個体差をあらかじめ考慮に入れることで、同じ情報でも受け取り方が違っていることを可視化できることによって、個体差を考慮したインターフェイス設計につなげることが可能になります。
また、呼気のCO2含有量の推移や心拍音の変化、脳波の変化によって、ストレス状況に置かれているかどうかが判断できます。過激なシーンのあるホラー映画を流した時、会場のCO2の濃度が上がった事例が紹介されました。同じ映画でも、一人で見るよりも、複数人で見るときのほうが、脳波の波形が相関するなど、体験する環境下によって生体反応は違ってくる事例も示されました(図2)。
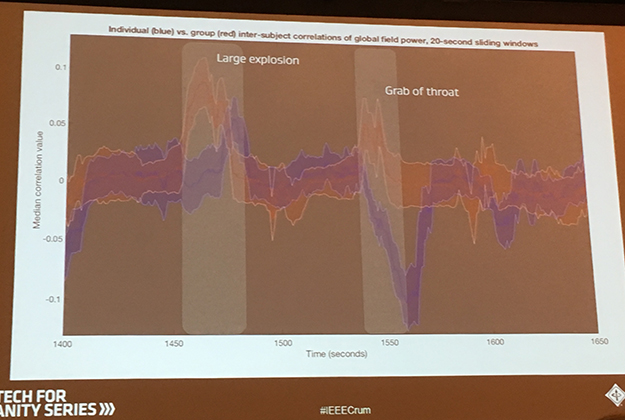 (図2)閲覧状況による脳波の動き
(図2)閲覧状況による脳波の動き【出典】Empathetic Technology and the End of the Poker Face:Poppy Crum氏(Dolby Laboratories)
上記のセッションで撮影
未来予測を行うフューチャーリストAmy Webb氏のセッションでは、ウォルマートが2018年に特許出願したと言われている生体反応計測ショッピングカートの事例が紹介されました(図3)。
こちらは、ショッピングカートの持ち手の部分にセンサーを入れ、心拍数や体温、歩行スピード、ハンドルを掴む時の力などを計測します。取得したデータを解析し、店舗内でどういう心理状況になっているか把握して、「探し物がどこにあるかわからずイライラしている」といったサポートが必要な状況にある顧客を見つけ、店員が対応に向かうということを想定しています。
「欲しいものを効率的に見つける」という目的だけではなく、個人の生体データのパターンから認証を行い、その人の好みや買い物パターンを察知したレコメンドを行うようなリアル世界での買い物体験がこの先の展開にあるのではないかと思います。
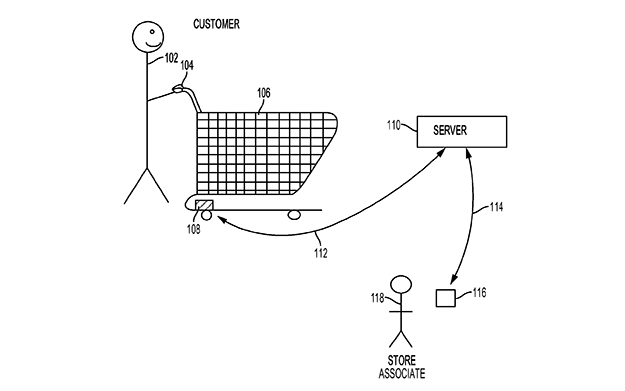 (図3)ウォルマートが特許出願した生体反応計測ショッピングカート
(図3)ウォルマートが特許出願した生体反応計測ショッピングカート【出典】Featured Session: 2019 Emerging Tech Trends Report:Amy Webb氏(Future Today Institute)
上記のセッションで紹介された事例の特許関連ページより引用
たとえ同じ出来事や現象であっても、個体差と、周りの騒音や風景、気圧、温度で、脳における感じ方は違ってくるため、生体データそのものは個人への依存度が高いデータになることが特徴となります。このため、センサーで計測するだけではなく、以下の工夫が必要になります。
- 周囲の環境に関するデータも合わせて取得する(部屋の環境、どんな関係値の人と一緒の空間にいるのか等)
- スナップショットのデータにより生体反応の前提条件を把握しておく(その人の身体の特徴、育った環境などの文化的背景、想定内と捉えられる程度の経験値の有無)
- 基準値を決めた時系列推移のデータで観測する(その日の健康状態や心理状態が普段と比べてどのように違うのか、時間の経過で変化したものを捉える)
Poppy Crum氏は、生体データの活用の可能性を語る一方で、テクノロジーの活用の意義についても述べました。
テクノロジーは、現在One-fits-allを目指しているが、テクノロジーはひとつでも、インパクトやベネフィットは個人それぞれに依存する。生体データは、個人の状況に適した形でサービスを提供すること=Contextual Optimizationの実現に寄与できる。これにより、ユーザー体験がより豊かになり、人間同士がこれまでよりも深く理解し合え、協力しあう社会に役立てて欲しい。
データやデータを使った自動意思決定システムへの規制・ガイドライン化
なぜPoppy Crum氏は最後に「協力しあうことに役立ててほしい」と言ったのでしょうか。彼女は生体データで様々な感情や状況を読み取れるようになったことについて次のように表現しました。「The end of poker face. This is the era of the empath.」 同様に、Amy Webb氏も「Privacy is dead.」と表現しています。
データで様々なことが把握でき、AIを使った自動的な意思決定システムがあらゆる分野で提供されるようになってきたことで、そのシステムは人間を幸せにしているのか、という観点の議論は、以前からありましたが、今回のSXSW2019ではホットトピックスとして様々な立場から考察する内容が目に付いたと思います。
今回見て回ったセッションで、今の段階で議論をするべきであるとして挙げられていた課題は、大きく3つあります。
- プライバシー
- 自動意思決定システムの透明性・説明責任
・アルゴリズム(何を予測、推定するか)
・データセット
・開発プロセス- 信頼できるAI
・法令遵守
・倫理的(バイアス除去、結果の公正さ)
・技術的に堅牢
AIを使ったシステムを開発する企業や担当者は、1はもとより、2と3をも考慮しながら取り組む責任が問われています。欧米における各国・企業・団体の取り組み動向をまとめたものが以下の図です。
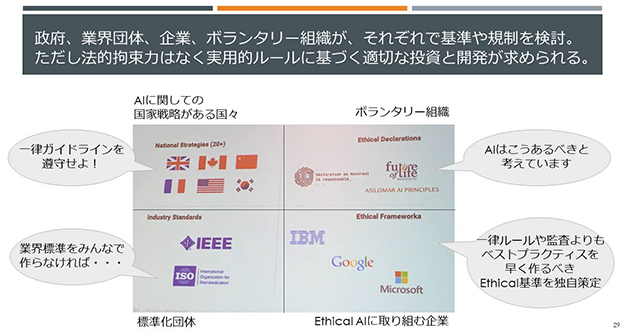
AI規制に関する立場別のマッピング
【出典】
Dear Gov’t: Regulate Us! Sincerely, AI Industry:Jean-François’ Gagné氏(Element AI)
Bias in, Bias Out: Building Better AI:Ashley Casovan氏(Government of Canada)、Kasia Chmielinski氏(The Data Nutrition Project/MIT)、Vikash Mansinghka氏(MIT)、M. Alejandra Parra-Orlandoni氏(Quantumblack a McKinsey Company)
上記のセッションで撮影・聴講した内容から筆者作成
中でも、カナダ政府が、2019年4月1日に施行した自動意思決定システムに関する指令は話題となりました。この指令は、2020年4月1日以降に開発・調達される自動意思決定システムは、この指令に準拠することが求めるものです。
おもに以下の項目を評価するとしており、後述するAlgorithmic Impact Assessmentを開発着手前に行うことを求めています。
- 何に関して決定を下したか
- どんな種類のデータが収集されていたか
- 目的に即してどのようにデータを集めたか
- 正しいパラメータが設定されているか
- データに偏りがないかどうか
- 上記のようなことが考えられているか
Algorithmic Impact Assessmentの評価項目は57個の質問にチェックボックス形式で回答することで最終的にインパクトレベルと求められる対策ガイドラインが判定されることになっています。これを読むとソースコードの公開などビジネスロジックの公開に近い内容も含まれ、すべてを詳らかにすることを求める内容であることがわかります。
「自動意思決定システムに関する指令」の内容
1.Algorithmic Impact Assessmentを開発前に完了すること(以下は大項目)
開発組織、関与する人材の的確さ
意思決定に人の介入が含まれているか
便益やサービス提供、制限の理由についての説明
提供前にデータからのバイアスの除去、結果が公正かテストすること
結果のモニタリング体制の構築
人材育成とドキュメント化
継続性があるか2.透明性
事前にユーザーに自動意思決定システムが動いていることを通知すること
意思決定の後にどのように意思決定したか、その理由を説明すること
使うソフトウェアの適切性
ソースコードの公開3.品質保証
データにバイアスがないか、結果が公正か、事前にテストし、モニタリングすること
データソースと収集方法が適格か評価すること
専門家のレビューを受けること
企画設計、実装、運用に携わる社員の教育をすること
危機管理システムの構築
セキュリティ対応
法的違法性がないかの確認
人間の介入があって決定される仕組みを作ること4.体制
利用者が異議申し立てや問い合わせを行える体制を作ること5.報告義務
自動意思決定システムを使ったことによる効果を、カナダ政府にレポートすること【出典】カナダ政府のページをもとに筆者作成
こうした政府関係のガイドライン化は、企業の個別の状況やビジネススタイルは考慮されず、一律ルールになりがちです。そのため、アメリカのテックジャイアントと呼ばれる企業やコンサルティング会社は、自社独自基準の制定やクライアントと合意を取ったガイドラインを制定し、自律的に行う方向に動いています。
EUにおけるAI倫理基準に関する国際会議に出席したカナダのAI開発企業Element AI社のCEOのセッションでは、Ethical AIを目指すために、政府による規制は必要との立場を取っています。スタートラインは人権を主軸に考え、原理原則はテクノロジー企業主体、活用段階や標準化は関連する産業を主体として進め、政府も関与するという意見で、どちらかといえばユースケースを作りながら進める形を提唱しています。
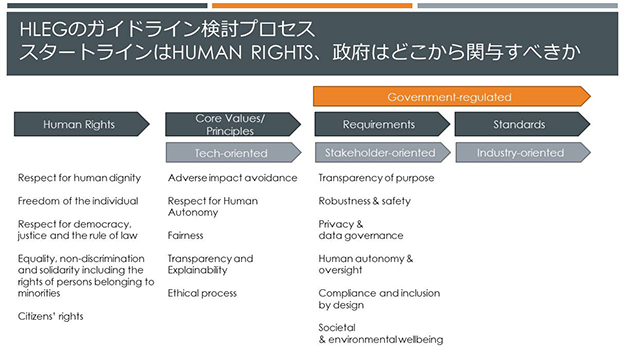 AI規制に関するステップ別の関与者
AI規制に関するステップ別の関与者【出典】Dear Gov’t: Regulate Us! Sincerely, AI Industry:Jean-François’ Gagné氏(Element AI)
上記のセッションで撮影し筆者加筆
最後に、Ethical AI関連の取り組みで個人的に面白いと思ったものを取り上げたいと思います。MIT Media Labの支援を受けているボランタリーなプロジェクト「Data Nutrition Project(https://datanutrition.media.mit.edu/index.html)」です。カナダ政府やMIT、AIコンサルティング会社によるEthical AI構築のためのガイドラインに関するパネルディスカッションで紹介されました。
よく、AIに学習させるデータがノイズだらけの「ゴミデータ」であれば、ゴミのような結果しか出てこない(何の役にも立たないモデルになってしまう)ことを、「Garbage in, Garbage out」と表現することがあります。これと同じように、データにバイアスが含まれていると、バイアスを含んだ結果が出力され、結果の公平性が担保できません。これを「Bias in, Bias out」と問題定義し、それを解決するために、使用するデータの特徴を栄養成分表示の形式を使って共有しようという取り組みがData Nutrition Projectです。
データセットを用意したら学習させる前に「データの質」を評価し、決められたフォーマットで記録に残します。モデル開発中の試行錯誤の中でデータの問題を疑うときにいつでも立ち戻れるようにすることで、最終的にAIの品質を向上させることにつながります(図4)。
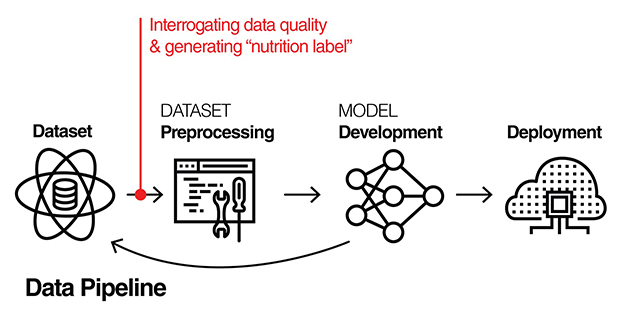 (図4)AIを使った自動意思決定システムの流れとデータパイプライン(データの取得・解析・学習用データ加工の一連の工程)
(図4)AIを使った自動意思決定システムの流れとデータパイプライン(データの取得・解析・学習用データ加工の一連の工程)【出典】Data Nutrition Project Webサイトより
Data Nutrition ProjectのWebサイトにはプロトタイプがあります。データの成分として表示されているのは、データ取得元団体と連絡先、カラム名、欠損割合、カラム同士の相関関係など統計情報が用意されています。これが一覧化・可視化されることで、データの前提がわかり、結果の公平性に影響のありそうなバイアスを除去するために、どのような前処理や補正をするべきか、適切なアルゴリズムは何か、の判断材料にできます。またこれを世界的に共有する形にすれば、AIを使ったシステム自体の前提や結果の妥当性について、建設的な議論ができると思います。
 Data Nutrition Projectのデータ成分表サンプル
Data Nutrition Projectのデータ成分表サンプル【出典】Data Nutrition Project Webサイトより
▶プロトタイプ
このように、一口にEthical AIといっても、データの話やアルゴリズムの話、運用、規制の話など考慮すべきことは多岐にわたります。
この中で私が大事だと思うことの一つはData Nutrition Projectに代表されるデータ品質の担保だと考えています。使うデータの特性や前提を理解して、AIに学習させるという基本的な概念の理解は、まだまだ一部のデータサイエンス関係者の中だけで共有されている概念だと感じることが多いからです。
普段からデータに触れる機会の多い立場であれば、感覚値として「データの質が結果を左右する」ことを理解できています。しかしビジネスの現場には、同じ感覚値を持っていない同僚やクライアント企業と合意を得ながら仕事を進めることが普通です。「このデータがあるから何か活用できないか」「とにかく大量にデータをAIに食わせたら結果が出るのでしょう?」という会話は良くあることですが、目的に即した適切なデータになっていなければ、使っても「誰も幸せにしないAI」が出来上がってしまうことは自明です。このことを理解してもらうために、一つ一つ簡易分析をして説明したりすることは、全体のスピードを落としてしまいます。
データサイエンスの根幹部分に関わる人々が、本来の「科学的な業務」に専念できるためには、データが目的に即した適切なものであるか、データ自体の品質や前提理解が大事であることの啓蒙活動が必要だと考えています。
その意味で、データを学習させる前に、可視化と統計情報を一覧化するための共通フォーマットの作成をしている取り組みが起きていることは、全体を通して興味深かったです。これが完全な形とは思っていませんが、現在様々な企業の実務家や研究者、教育関係者、政府関係者、データサイエンスコミュニティとの対話を通じ、共通化に向けた動きをし続けていくようです。データ界隈の一員としては、同様の動きが多数出てきて、現場で使いやすい最適なフォーマットが出来上がっていくことを期待してやみません。
txt:後藤真理絵(ヤフー株式会社) 構成:編集部


























