





Adobeの本拠地である米国にて、10月28日から30日まで、「Adobe MAX 2025」が開催された。昨年2月にAdobe MAX 2025はやったのでは?と思われるかもしれないが、あれはAdobe Japan主催のもので、実質的には、Adobe MAX Japan 2024が次の年に持ち越したために2025になったものである。本家本元のAdobe MAX 2025が、このイベントというわけだ。筆者はこのイベントに参加するために、26日から現地入りしている。
28日にDay1のキーノートが行われたが、なんと3時間という長丁場である。それだけ見せるものが多いということなのだが、同時に全体像を理解させるまでこれだけの説明をしなければ伝わらないという、非常に複雑なキーノートであった。
すでに各メディアでは速報レベルの記事が出始めているところだが、個別のソフトウェアのアップデートを語っても、Adobeが考える次世代のワークフローは理解できない。本記事では、今回発表された多くの技術の中から、クリエイティブワークフローに関わるものを中心に、全体として何が起こっているのかといった俯瞰の視点から、その全体像を解説する。

AIでクリエイティブ全体がつながる
クリエイティブの世界では、生成AIをどのように使っていくかが課題となっている。ご承知のように一部の生成AIは著作権的な問題を抱えており、プロのクリエイターが使いづらくなっている。だから学習ソースがライセンスされたものに限られるFireflyを使いましょう、というのがこれまでのAdobeのメッセージであった。
これまでAdobeでは、Fireflyだけでなく他社の生成AIも使えるようにするという方向性を示していたが、それらをどうインテグレートするのかが注目されていた。今回のAdobe MAXでは、そのあたりのビジョンが示された。
まずAdobeの生成AIで中心的存在となる「Firefly」では、Adobeモデル、パートナーモデル、カスタムモデルの3つが提供されることとなった。Adobeモデルでは「Adobe Firefly Image Model 5」が登場、4メガピクセルまでの高解像度画像生成に対応し、プロンプトでの「編集」機能を持つ。生成ではなく、画像を認識しての編集作業が可能になった点は、これから説明する機能に大きく関係するので、ご記憶願いたい。

パートナーモデルは、現在我々が注目する生成AIのほとんどを網羅している。これらは、モデル選択画面から、候補として選べるようになるわけだが、ポイントは他社製生成AIの使用クレジットも、それぞれ個別に購入する必要はなく、Adobeの生成クレジットで支払うことができる。あちこちに課金する必要がないということである。どのモデルに、どのような作業をさせたら何クレジットかかるのかといったところは他社のルールもあるので、損だ得だと言った違いはあるものの、契約形態や支払いメソッドがシンプルになるだけでもメリットがある。

画像生成において、自社でも生成AIを開発しつつ、これだけ多くのモデルに一度に対応したプラットフォームは今のところ他にない。同時にこれだけ多くのパートナーとライセンスを結んだ理由は、それぞれできることの得意不得意や、テイストに違いがあるからだ。1つの生成AIですべての表現や処理がカバーできるわけではないというのは、当然の考え方だ。
カスタムモデルは、クリエイター個人や、制作会社自体が持つ過去の作品を学習させることで、同じテイストでの画像生成を可能にするモデルだ。これはデモの写真を使って説明したほうが早いと思うが、デモンストレータのポールさんの作風は、花を多くあしらうというものである。これらの過去の作品を学習させ、専用モデルを作成する。
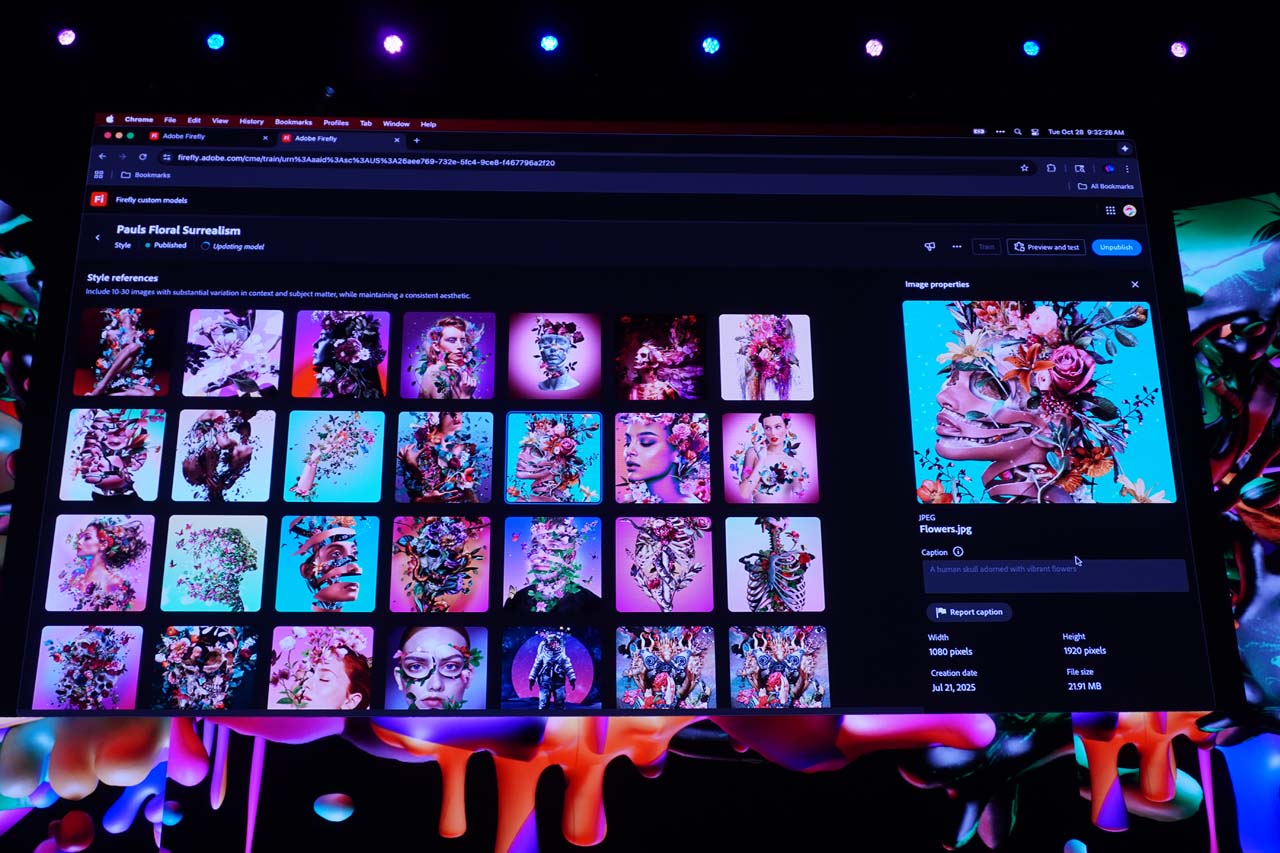
そして新たな素材をベースにカスタムモデルで生成させると、その作風で新たな画像を生成してくれる。



こうした生成AIの使い方は、直接的な使い方である。一方で制作ワーククフローの中にAIを取り入れていくという考え方が、「AIアシスタント」ということになる。このAIアシスタントは、複数のソフトウェアが対応する。
例えばPhotoShopでは、右側にあるプロンプトから、画像編集に関わることをAIにリクエストできる。例えば「主要な被写体を除いて全体の輝度を下げて彩度を上げて」と指示すれば、AIが主要な被写体をマスクで切り取ってレイヤーに分け、それ以外の部分のコントラストをいじる、といった動作になる。これまでは人間が手作業でやらなければならなかったマスク切りとレイヤー分けという作業が一瞬で終わる。

これが、「編集に対応するAI」だ。多くの生成AIは、画像全体をいっぺんにいじってしまうので、維持したかった部分までなくなってしまったりするようなことが起こるが、編集に対応するAIは、レイヤー構造を維持したままで、特定のレイヤーのみをいじれるという強みがある。
さらに、出来上がった画像のレビューを依頼できる。空が印象的で被写体が際立ちますねと言った感想のほか、テキストはもう少し色を濃くするか、ドロップシャドウをつけたほうがいいですよ、といったアドバイスをしてくれる。もちろん、「じゃあそうして」と依頼すれば、その通りに修正してくれる。

会場で最高にウケていた機能が、AIによるレイヤーのリネームだ。作業していると、レイヤー名がレイヤー3のコピーとか、レイヤー3のコピーのコピーとか、だんだんそのレイヤーが何をやっているのか、わけががわからなくなってくる。この時AIに、効果に応じた名前にリネームしてと依頼すれば、「背景のコントラストをいじったレイヤー」とか「○○の文字」とかいった名前にリネームしてくれる。こうした機能は、AIアシスタントの実装が今後PremiereやAfter Effectsに広がることで、トラックやレイヤーのリネームに応用できるようになるだろう。

他社のAIとのコラボレーションも可能になる。Fireflyは画像・映像・音声に特化したAIなので、企画やコンセプトの相談や下調べみたいなことには向かない。こうしたブレインストーミングや壁打ちみたいな作業は、ChatGPTを使う人は多いだろう。
ChatGPTで企画を練ったあと、プリプロダクションとして仮に絵を作ってみたいということになると思うが、その時にChatGPTから離れて今度はFireflyに生成コマンドというか、企画内容を入力し直しというのは、馬鹿げている。

そこで新しい機能として、ChatGPTからAdobe ExpressやPhotoShopを呼び出して、企画内容をそのままコマンド指示できるようになる。

これはAdobe ExpressやPhotoShop Web版のAPIを呼び出すことで実現している。これまで、なんでAdobe Expressはローカルアプリがないんだとか、逆にPhotoShopのWeb版なんて誰も使わんやろと言われてきたわけだが、こうして他のAIから呼び出すという機能を実現するための壮大な伏線だったわけだ。
動画編集の未来像
動画関連の発表といえば、従来からデスクトップ版のPremiere Proが中心となっているところだが、時期バージョン26からはProが取れてPremiereという名称になる。モバイル版も含め、Premiereファミリーを形成する格好となる。とはいえ、デスクトップ版が最終的な母艦であり、そこがプロ向けであることは変わらない。
デモではオブジェクトマスクが大きくフィーチャーされていたが、これは9月からベータ版で実装されてきた機能であり、新規お目見えというわけではない。一方全くの新機能で大きく受けていた機能は、音声の差し替え機能、Auto-bleepだ。これはクリップからテキスト起こししたしゃべりの中から、放送禁止用語やプライバシーに関わる固有名詞などマズい言葉を検索し、その部分をピー音など別の音声に差し替えるというものだ。ピー音だけでなく、アヒルの鳴き声など別のタイプの音も選択できる。

キーノートでは動画関係の新機能は若干薄めであったが、2日目の夜に行われたSneaksでは、多くの動画関係の技術が発表された。Sneaksは開発中の機能を事前公開するイベントで、反応の大きさを見て実装するかどうかが決まるという、ある意味選挙のようなイベントである。

「Project Frame Forward」は、動画の中の1つのフレーム画像内でオブジェクトを選択し、それを削除する。ここまでは静止画処理だが、その処理を動画クリップに反映させることで、動画全体から特定のオブジェクトを消去するという機能だ。これは昨年からPremiere Proに実装予定とされていた、「オブジェクトの削除機能」を実現するプロジェクトである。
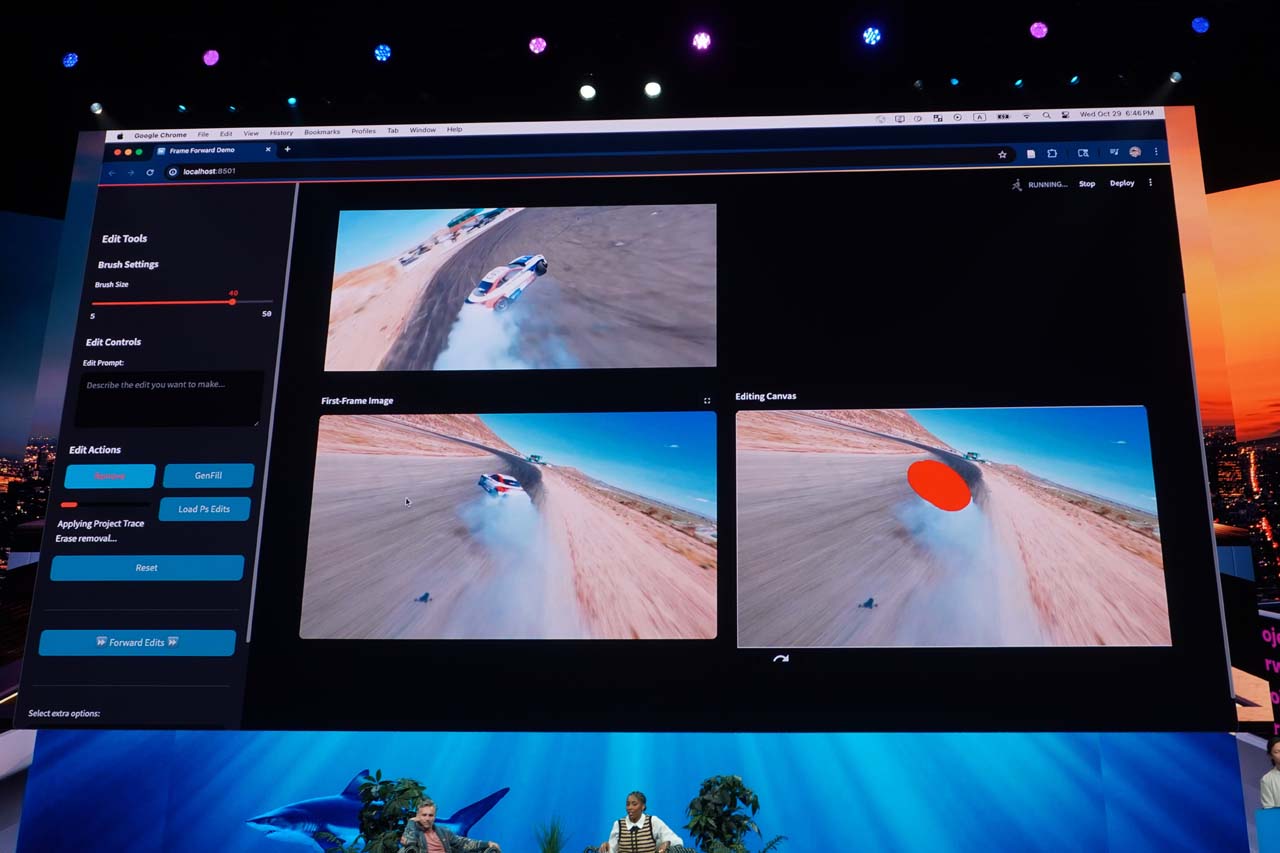

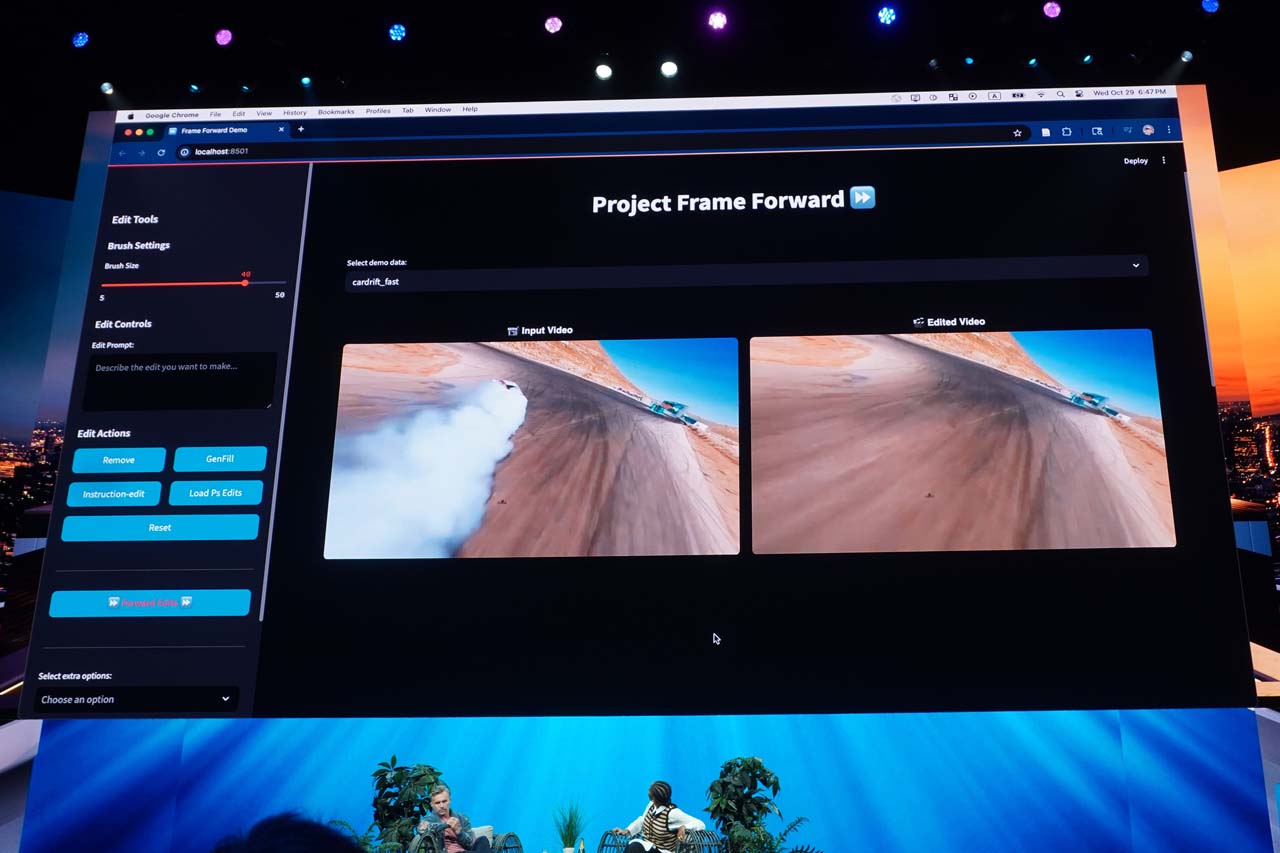
この機能は、オブジェクトの削除とは逆に、生成AIで新たなオブジェクトを加えて、それを動画全体に反映させることもできる。最初から動画全体を扱うのではなく、まずは静止画ベースで処理したのち、そのアルゴリズムを使って全フレームを一気に高速処理するという方法論のようだ。


Project Sound Stagerは、音声のないCGのようなコンテンツに、生成AIを使ってSEや音楽を当て込むという機能だ。最初にカット割を分析したのち、各カットの特徴に合わせてSEを生成する。これはいちいち個別にプロンプトで指示をするわけではなく、AIが映像の状態を分析して、自動で音を生成するところがポイントである。サウンドが気に入らなければ、同時に生成された別の候補から選んで差し替えることもできる。


Project Clean Takeは、クリップの音声を複数の要素に分解し、それぞれをトラックに展開して調整できるようにするという機能だ。例えば同時に収録されてしまったBGMを、許諾が取れた別の似たような音楽に差し替えたり、不意に入り込んできたBGノイズを削除したりといったこともできる。
さらに強力な機能は、人のしゃべりの中で特定の部分のイントネーションを変更できる機能だ。例えば上がり調子の疑問系で喋った言葉を、語尾の音程を下げて断定的にするといったこともできる。例えばインタビュー音声の編集では、編集したところの言葉のイントネーションが合わないといった問題は、頻繁に発生する。こうした部分を個別に調整できるようになる。

特定の単語を、別のものに差し替える機能もある。言い間違えたところを、本人の声で差し替えできるという機能だが、これはソースの真正性に関わる部分なので、その点ではちょっと議論があるところだ。

また、ナレーションをはつらつとしたトーンに変更したり、つぶやきのようなトーンに変更したりといった、「エモーション」の変更も可能だ。

音声処理は、昨今ではMAミキサーや音楽効果など専門家への分業が減り、編集者が自分でやることが増えている。だが音声処理の経験がない場合は、なかなか四苦八苦するところだ。こうした部分をAIが助けてくれるようになる…かもしれない。
生成AIの利用は、これまではプロンプトをガリガリ書けば様々な処理に対応できる、という方向性だった。ただそれは多くのクリエイターや、専門のプロフェッショナルの作業としては馴染まない。よってAIで可能な処理を、専門性を保って使いやすい形で、一種のエフェクタやプラグインのような格好で提供していくという方向性にあるように思えた。
WRITER PROFILE





























